Outubro 2008
Monthly Archive
Outubro 31, 2008
Posted by Antero Neves under
Cabeçalhos,
Rodapés,
Sobre LaTex | Etiquetas:
fancyhdr,
\cfoot,
\chead,
\fancyfoot,
\fancyhead,
\lfoot,
\lhead,
\rfoot,
\rhead |
[12] Comments
O package fancyhdr é de extrema utilidade quando queremos personalizar o cabeçalho e rodapé de um texto.
Toda a informação é inserida no preâmbulo do documento e, claro está, começamos por carregar o package:
\usepackage{fancyhdr}
Depois, temos que dizer que queremos que o estilo da página siga a fórmula dada pelo fancyhdr. Escrevemos então que:
\pagestyle{fancy}
A partir de agora temos que ter em mente duas coisas
- que os cabeçalhos e os rodapés estão divididos em 3 partes, esquerda, centro e direita;
- que os cabeçalhos podem ser diferentes dependendo da paridade da página (se é par ou ímpar).
Outra coisa que ajuda sempre é saber que em inglês left é esquerda, center é centro e right é direita, para além de que header é cabeçalho e footer é rodapé.
Vamos então definir o que fica em cada parte. Neste exemplo estou a considerar um documento com um só lado, ou seja, é tudo igual independentemente da página ser par ou ímpar. Escrevo então:
\lhead{O que quero no cabeçalho parte esquerda}
\chead{O que quero no cabeçalho parte central}
\rhead{O que quero no cabeçalho parte direita}
\lfoot{O que quero no rodapé parte esquerda}
\cfoot{O que quero no rodapé parte central}
\rfoot{O que quero no rodapé parte direita}
Se não quiser nada em alguma das partes, deixo o conteúdo vazio, por exemplo, se quiser que não apareça nada na parte esquerda do rodapé, escrevo:
\lfoot{}
Ou então…
Para ter a certeza que todas as parte que quero vazias, aparecem efectivamente vazias sem ter que as definir, escrevo o seguinte:
\fancyhead{}
\fancyfoot{}
Estes dois comandos preenchem todas as partes que não definimos com o que quer que esteja entre as chavetas.
Exemplo:
\fancyhead{Viva}
\fancyfoot{}
\chead{Mais}
\lfoot{Muito}
\rfoot{Mais}
O cabeçalho definido no exemplo teria à esquerda e à direita a palavra Viva (definida no \fancyhead) e ao centro a palavra Mais; o cabeçalho teria à esquerda a palavra Muito, ao centro fica vazio (devido ao \fancyfoot estar vazio) e à direita a palavra Mais.
Para trabalhar com cabeçalhos pares e ímpares, usamos exactamente os mesmos comandos só que ao introduzir a parte par usamos [] e para a parte ímpar usamos {}.
Exemplo:
Para definir a parte esquerda de um rodapé que em página par é Viva e em página ímpar é Mais, escrevo:
\lfoot[Viva]{Mais}
To be continued… 🙂 (Heroes a mais!)
Outubro 29, 2008
De quando em vez aparece uma palavra cuja hifenização, ou divisão silábica se preferirem, está mal feita aquando da mudança de linha.
Para resolver esse tipo de problemas podem recorrer à divisão manual da palavra.
De que forma se faz a hifenização manual?
Muito simplesmente colocando um \- (barra hífen) entre cada sílaba (ou entre aquelas que estão a dar problemas.
Exemplo:
Tinha um documento que me dividia a palavra conhecimento da seguinte forma: Conhec (fim de linha) imento, para corrigir, no documento tex, escrevi a palavra assim:
Co\-nhe\-ci\-men\-to
E… problema resolvido!
Outubro 28, 2008
Encontrei ontem um package que altera a forma como os capítulos são abertos. Em vez do tradicional “Capítulo 1” sem qualquer formatação especial, este pacote permite alterar a forma como esta informação é apresentada.
O package chama-se fncychap e, claro está, para o adicionar temos que colocar a linha
\usepackage[opção]{fncychap}
no preâmbulo. A opção é o tipo de formatação que queremos usar:
SonnyConnyLennyGlennRenjeBjarneBjornstrup
Para todas elas há uma versão para \chapter e \chapter*. A imagem seguinte mostra algumas destas configurações.

Podem encontrar a documentação relativa a este package aqui.
Outubro 23, 2008
Uma coisa que me aborrece é escrever texto matemático inserido numa linha de texto. O que normalmente acontece é o texto matemático ficar mais pequeno que o resto do texto, e isto acontece mais quando trabalhamos com fracções ou raízes. Mas não é um problema exclusivo do texto matemático em linhas.
Já há algum tempo, numa procura por resolver este problema encontrei o seguinte comando:
\displaystyle
e usa-se da seguinte forma:
texto texto texto $\displaystyle texto matemático$ texto texto texto
Exemplo:
$\displaystyle A(x)=\frac{x^3+2x+1}{x-x^2}$\,.
Resultado sem \displaystyle:

Resultado com \displaystyle:

Bom… isto até é muito bonito, mas o que me “atormentava” era o facto de ter que inserir em todos os ambientes matemáticos o comando \displaystyle, e foi a solução para este problema que me fez escrever este post.
Recorremos ao comando \everyXXX !!!
Inserimos no preâmbulo a seguinte linha:
\everymath{\displaystyle}
e… temos o comando \displaystyle aplicado a toda a matemática! E já não precisamos de o escrever mais!
Clique em mais para continuar… 🙂
(mais…)
Outubro 22, 2008
Ao longo de um trabalho podemos usar várias fórmulas e usar determinada notação. Torna-se por isso útil que se esclareça o leitor, seja ele versado ou não na matéria, sobre o que significam todas aquelas letras. O 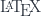 permite que se introduza uma lista da numenclatura – ou notação, como lhe quiserem chamar – num qualquer local do documento.
permite que se introduza uma lista da numenclatura – ou notação, como lhe quiserem chamar – num qualquer local do documento.
Temos, claro está, o habitual pacote, ou package, para carregar. Desta feita chama-se nomencl.
Assim, adicionamos ao preâmbulo a linha:
\usepackage{nomencl}
mas, para além desta linha, vamos adicionar também no preâmbulo uma instrução para ser elaborada a lista:
\makenomenclature
De seguida começamos o nosso documento como habitualmente e, no sítio onde quisermos introduzir a lista, colocamos a seguinte instrução:
\printnomenclature
Mas como são introduzidas as entradas na lista?
Normalmente essas entradas são feitas no local onde aparecem, pela primeira vez, as letras a “descodificar” e para isso usa-se o comando
\nomenclature
A introdução faz-se, então, do seguinte modo:
\nomenclature{Símbolo usado}{Explicação do símbolo usado}
Exemplo:
\begin{equation}
A=\sqrt{s(s-a)(s-b)(s-c)}
\end{equation}
\nomenclature{$s$}{O semi-perímetro do triângulo (metade do
perímetro)}
Mas não é só isso… infelizmente há ainda um pequeno passo que torna o uso deste package um pouco traiçoeiro.
Para que a lista apareça, é necessário criar um ficheiro .nls a partir do ficheiro .nlo que foi criado usando as informações que estão no ficheiro nomencl.ist.
Confuso?? Se sim então basta saber que apenas é necessário correr a seguinte instrução:
makeindex <nome do ficheiro tex>.nlo -s nomencl.ist -o <nome do ficheiro tex>.nls
Como fazer isso? Bom.. acho que depende do sistema. Eu sei como o fazer no WinEdt…

Tal como mostra a figura, vão a Accessories e escolhem Run… ou então carregam directamente nas teclas de atalho Shift+Ctrl+R. E preenchem a janela que vos aparece:

Na primeira linha coloquei a instrução que indiquei acima (o meu ficheiro chama-se experiência) e na segunda linha coloquei o directório onde está gravado o ficheiro tex, penso ser isso o pedido :).
Há muito mais coisas que podem fazer com este package, para aprofundar o tema, consultem este pdf.
Pode também ser necessário alterar o nome da secção de Nomenclature para outro qualquer, como Nomenclatura (em português 🙂 ). Para isso, basta usar o conhecido \renewcommand:
\renewcommand{\nomname}{Nomenclatura}
Para saber mais sobre alterações de textos automáticos e não só consultar:
E já agora… podem também consultar a página da wikipedia sobre o Teorema de Heron. 🙂
Outubro 21, 2008
Para fazer uma tabela em gastamos muito tempo… pelo menos para mim é uma coisa muito aborrecida de fazer porque me perco um pouco entre os & 🙂
Descobri recentemente um add-in do MS Excel que facilita, e muito!, esta tarefa.
O ficheiro chama-se excel2latex e podem-no encontrar aqui. É só abrir o ficheiro xla no Excel, não sei se funciona também no OpenCalc (agradecia que se alguém experimentasse, deixasse um comentário) e fazer a tabela!
Claro está que tem algumas limitações, nomeadamente na formação da tabela e por isso não esperem fazer tabelas muito personalizadas com este add-in, ainda assim, para aquelas tabelas simples é muito útil.
Depois de fazermos a tabela como mostra a figura abaixo, seleccionamos a tabela e é só usar o excel2latex.


Depois podem escolhe ou gravar para um ficheiro ou então copiar o texto e colocar no vosso ficheiro tex.
Outubro 20, 2008
Para além do índice normal – a chamada tabela de conteúdos – podemos ainda acrescentar um índice de tabelas que tivermos no documento ou então um índice de imagens.
O comando para introduzir um índice de tabelas é:
\listoftables
Se quiserem introduzir uma lista de figuras, então escrevam:
\listoffigures
Claro está que os comandos são inseridos onde queremos que os índices apareçam 🙂 .
Estes comandos funcionam nas classes report, book e thesis.
Outubro 18, 2008
Posted by Antero Neves under
Espaçamentos | Etiquetas:
1.5,
duplo,
espaçamento,
simples,
\bigskip,
\doublespacing,
\medskip,
\onehalfspacing,
\setspace,
\singlespacing,
\smallskip,
\vspace |
[4] Comments

Subscrevam o canal do youtube em: https://www.youtube.com/c/anteroneves

Mais informação no vídeo acima.
É muito usual alterar o espaçamento entre linhas de simples para 1,5 – pelo menos, na maior parte dos meus trabalhos académicos tive que o fazer – e em isso faz-se usando, obviamente, um simples comando 🙂 .
Para começar, é necessário chamar um package no preâmbulo. O package é o setspace. Sendo assim, a linha a adicionar será:
\usepackage{setspace}
Depois disso, ao longo do texto podemos proceder a alterações no espaçamento entre linhas colocando simplesmente um dos seguintes comandos:
\singlespacing Para um espaçamento simples\onehalfspacing Para um espaçamento de 1,5\doublespacing Para um espaçamento duplo
Esses comandos terão efeito até à proxima instrução que altere o espaçamento.
Exemplo:
\begin{document}
\onehalfspacing
Primeiro bloco de texto
\doublespacing
Segundo bloco de texto
\end{document}
O Primeiro bloco de texto terá um espaçamento de 1,5 e o Segundo bloco de texto passará a ter duplo.
Tenho já uma breve referência a comandos sobre espaçamento na NOTA 3 deste post.
Outubro 16, 2008
Só agora me apercebi que nunca disse aqui como fazer uma tabela de conteúdos ou seja, um índice, no .
Mea culpa. Ainda por cima isto até é uma coisa bastante importante e foi dos primeiros factores que me levaram a gostar tanto de trabalhar com em , e explico porquê: eu sei que com o MS Word também é possível fazer um índice automaticamente (sei porque os céticos do me dizem) mas o que é facto é que quando estou a trabalhar com o Word eu nunca faço nada como devia fazer, é muito facilitador, tanto que depois nunca sai nada de jeito!! Com o não é assim. Temos que fazer tudo direitinho e depois, como o trabalho foi sendo feito ao longo do nosso texto, parece que é muito menos cansativo.
Mas vamos ao que interessa 🙂
Para que nos apareça uma tabela de conteúdos, apenas temos que escrever o seguinte comando onde queremos colocá-la:
\tableofcontents
Normalmente coloco-a logo a seguir ao título, autor e toda essa informação inicial, ou seja, a seguir ao comando \maketitle.
NOTA: porque muitas vezes é necessário numerar alfanumericamente estas páginas, pode ser útil consultar o post: Alterar o tipo de numeração, e também, para controlar a numeração, ver: Alterar a númeração de páginas…
Exemplo:
\documentclass[a4paper,12pt]{report}
\usepackage[latin1]{inputenc}
\usepackage[portuguese]{babel}
\author{Antero Neves}
\title{Exemplo de Índice}
\date{\today}
\begin{document}
\maketitle
\tableofcontents
...texto...texto... com secções e subsecções, etc...
\end{document}
Outubro 7, 2008
A primeira coisa que temos de saber quando queremos alterar o símbolo usado no ambiente itemize, é que este símbolo já se altera de acordo com o nível do item. Por norma, no primeiro nível o símbolo é uma bola negra, no segundo é um traço, no terceiro um asterisco, no quarto um ponto, e não experimentei mais (para além de achar que já é pouco correcto mais níveis 🙂 ).
Visto isto, é claro que há um comando que serve para identificar o símbolo de cada nível que quisermos personalizar. Esse comando é \labelitem que será acompanhado pela indicação do nível em numeração romana, ou seja, se pretendermos alterar o símbolo do nível 1, o comando ficará \labelitemi; o nível 2, \labelitemii, etc.
Agora, para alterar o símbolo, temos de recorrer à instrução \renewcommand.
O exemplo que vou usar é para alterar o símbolo do nível 1:
Exemplo:
\renewcommand{\labelitemi}{$\star$}
\star fica entre $ porque é um símbolo usado apenas em notação matemática.
No fundo, o que estamos aqui a fazer é, renovar a instrução \labelitemi (que tem por definição um símbolo associado) pelo símbolo de uma estrela.
Se esta linha for introduzida no interior do ambiente itemize, por exemplo:
\begin{itemize}
\renewcommand{\labelitemi}{$\star$}
\item Primeiro item
\item Segundo item
\item Terceiro item
\end{itemize}
então apenas os itens deste ambiente serão afectados. Mas se a mesma linha for introduzida fora do ambiente então afectará todo o texto daí para a frente até que seja definido outro símbolo usando uma instrução análoga.
Página seguinte »






Deverá estar ligado para publicar um comentário.